项目简介
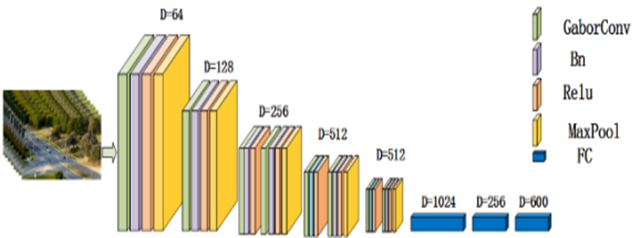
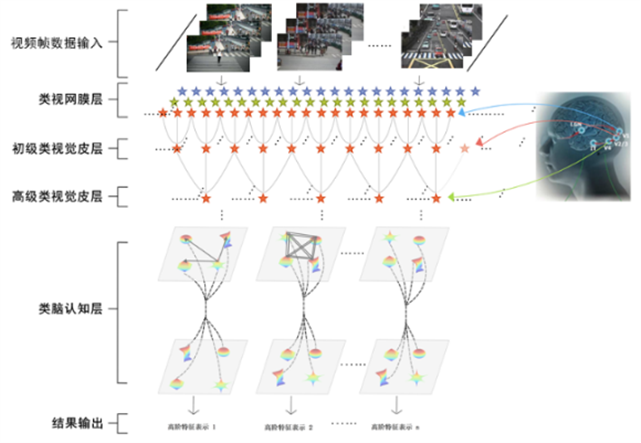
新媒体时代,网络视频呈爆炸式增长,已经成为人们工作、生活、娱乐必不可少的媒体资源,在带来丰富信息的同时,也引发了检索难、识别难、自动分析程度低等问题,导致视频所携带的大量信息难以高效利用,视频监管更因视频内容中的不良信息难以判断而陷入困局。鉴于此,本项目面向视频中特定事件的识别与理解,从事件语义定义、视频流特征空间描述入手,利用基于视频帧变化过程中的同源连续性原理,开展了视觉感知特性的仿生图像处理方法、融合数据驱动和知识驱动的联合学习以及典型事件的多样性与小样本学习等关键技术研究,通过模拟视觉皮层感受和量化同源连续性规律,建立了结合视觉感知特性的卷积神经网络模型和面向视频流的拓扑积神经网络模型。
本项目可应用于特定人物、特定物品、特定语义、精彩镜头、不良信息等网络视频内容的识别和检索等,可为政府机构、公安机关、广告传媒、社会公众提供定制化服务。
参考生物视觉皮层的响应特点与仿生认知过程中的同源连续性规律,结合数据驱动与知识驱动,以卷积神经网络为基础,提出了符合人眼视觉特性的视频事件特征表示技术;通过先验知识的引入,解决了视频分析中的小样本学习问题;分析连续视频帧在特征空间中的流形结构分布及变化规律,提出了基于覆盖学习的视频流拓扑积神经网络建模方法。
应用领域
全世界每天在Facebook上观看视频37亿个,YouTube用户每天观看视频5亿小时,2017年我国朋友圈日发表视频次数6800万, 2018年中国长视频用户已增长到5.6亿以上。对互联网视频的自动化处理,已成为视频理解的最大应用场景,市场潜力巨大。
相关图片